
يواصل مجال الذكاء الاصطناعي توسعه السريع، مع نماذج اللغة الكبيرة (LLMs) التي تظهر بشكل متزايد قدرات معرفية متطورة. من بين هذه النماذج، يبرز نموذج FractalAIResearch/Fathom-R1-14B كنموذج جدير بالاهتمام، حيث يضم ما يقرب من 14.8 مليار معلمة. تم تصميم هذا النموذج خصيصًا بواسطة Fractal AI Research للتفوق في مهام الاستدلال الرياضي المعقد والعام. ما يميز Fathom-R1-14B هو قدرته على تحقيق هذا المستوى العالي من الأداء بكفاءة تكلفة ملحوظة وضمن نافذة سياق عملية تبلغ 16,384 (16 ألف) رمز. يقدم هذا المقال نظرة فنية شاملة عن Fathom-R1-14B، مع تفصيل تطوره، وهندسته المعمارية، وعمليات التدريب، والأداء المعياري، وتقديم دليل مركز لتنفيذه العملي بناءً على الأساليب المعمول بها.
Fractal AI: المبتكرون وراء النموذج

Fathom-R1-14B هو نتاج Fractal AI Research، قسم الأبحاث في Fractal، وهي شركة رائدة في مجال الذكاء الاصطناعي والتحليلات يقع مقرها الرئيسي في مومباي، الهند. اكتسبت Fractal سمعة عالمية في تقديم حلول الذكاء الاصطناعي والتحليلات المتقدمة لشركات Fortune 500. يتماشى إنشاء Fathom-R1-14B بشكل وثيق مع طموحات الهند المتزايدة في قطاع الذكاء الاصطناعي.
طموحات الهند في مجال الذكاء الاصطناعي
يعد تطوير هذا النموذج ذا أهمية خاصة في سياق مهمة الهند للذكاء الاصطناعي (IndiaAI Mission). أشار سريكانث فيلاماكاني، المؤسس المشارك والرئيس التنفيذي للمجموعة ونائب رئيس مجلس إدارة Fractal، إلى أن Fathom-R1-14B هو عرض مبكر لمبادرة أكبر. قال: "اقترحنا بناء أول نموذج استدلال كبير (LRM) في الهند كجزء من مهمة IndiaAI... هذا [Fathom-R1-14B] مجرد دليل صغير على ما هو ممكن"، مشيرًا إلى خطط لسلسلة من النماذج، بما في ذلك إصدار أكبر بكثير يضم 70 مليار معلمة. يبرز هذا التوجه الاستراتيجي التزامًا وطنيًا بالاعتماد على الذات في مجال الذكاء الاصطناعي وإنشاء نماذج أساسية محلية. تشمل مساهمات Fractal الأوسع في مجال الذكاء الاصطناعي مشاريع مؤثرة أخرى، مثل Vaidya.ai، وهي منصة ذكاء اصطناعي متعددة الوسائط للمساعدة في الرعاية الصحية. لذلك، فإن إصدار Fathom-R1-14B كأداة مفتوحة المصدر لا يفيد مجتمع الذكاء الاصطناعي العالمي فحسب، بل يمثل أيضًا إنجازًا رئيسيًا في مشهد الذكاء الاصطناعي المتطور في الهند.
التصميم الأساسي والمخطط المعماري لـ Fathom-R1-14B
تستند القدرات الرائعة لـ Fathom-R1-14B إلى أساس مختار بعناية وتصميم معماري قوي، محسّن لمهام الاستدلال.
بدأت رحلة Fathom-R1-14B باختيار Deepseek-R1-Distilled-Qwen-14B كنموذج أساسي له. تشير طبيعة النموذج "المُقطرة" إلى أنه مشتق أكثر إحكامًا وأكثر كفاءة حسابيًا من نموذج أب أكبر، مصمم خصيصًا للاحتفاظ بجزء كبير من قدرات النموذج الأصلي، خاصة تلك المستمدة من عائلة Qwen المرموقة. هذا وفر نقطة انطلاق قوية، والتي قامت Fractal AI Research بعد ذلك بتعزيزها بدقة من خلال تقنيات ما بعد التدريب المتخصصة. لعملياته، يستخدم النموذج عادة دقة bfloat16 (تنسيق النقطة العائمة للدماغ)، مما يحقق توازنًا فعالًا بين سرعة الحوسبة والدقة العددية المطلوبة للحسابات المعقدة.
تم بناء Fathom-R1-14B على هندسة Qwen2 المعمارية، وهي تكرار قوي ضمن عائلة نماذج Transformer. نماذج Transformer هي المعيار الحالي لنماذج اللغة الكبيرة (LLMs) عالية الأداء، ويرجع ذلك إلى حد كبير إلى آليات الانتباه الذاتي المبتكرة فيها. تمكّن هذه الآليات النموذج من تحديد أهمية الرموز المختلفة ديناميكيًا - سواء كانت كلمات أو أجزاء كلمات أو رموز رياضية - ضمن تسلسل الإدخال عند إنشاء مخرجاته. هذه القدرة حاسمة لفهم التبعيات المعقدة الموجودة في المسائل الرياضية المعقدة والحجج المنطقية الدقيقة.
حجم النموذج، الذي يتميز بحوالي 14.8 مليار معلمة، هو عامل رئيسي في أدائه. هذه المعلمات، التي هي في الأساس القيم العددية المتعلمة ضمن طبقات الشبكة العصبية، تُشفّر معرفة النموذج وقدرات الاستدلال لديه. نموذج بهذا الحجم يوفر قدرة كبيرة على التقاط وتمثيل الأنماط المعقدة من بيانات التدريب الخاصة به.
أهمية نافذة السياق 16 ألف رمز
من المواصفات المعمارية الهامة هي نافذة السياق التي تبلغ 16,384 رمزًا. هذا يحدد الحد الأقصى لطول الإدخال المجمع والمخرجات التي يولدها النموذج والتي يمكن معالجتها في عملية واحدة. بينما تتباهى بعض النماذج بنوافذ سياق أكبر بكثير، فإن سعة 16 ألف رمز في Fathom-R1-14B هي خيار تصميم متعمد وعملي. إنها كبيرة بما يكفي لاستيعاب بيانات المشكلات التفصيلية، وسلاسل الاستدلال الشاملة خطوة بخطوة (كما هو مطلوب غالبًا في الرياضيات على مستوى الأولمبياد)، والإجابات الشاملة. الأهم من ذلك، يتم تحقيق ذلك دون تكبد التكلفة الحسابية التي تتزايد تربيعيًا والتي يمكن أن ترتبط بآليات الانتباه في التسلسلات الطويلة للغاية، مما يجعل Fathom-R1-14B أكثر مرونة وأقل استهلاكًا للموارد أثناء الاستدلال (inference).
Fathom-R1-14B فعال جدًا جدًا من حيث التكلفة
أحد أبرز جوانب Fathom-R1-14B هو كفاءة عملية ما بعد التدريب. تم ضبط الإصدار الأساسي من النموذج بدقة بتكلفة تقريبية تبلغ 499 دولارًا أمريكيًا. تم تحقيق هذه الجدوى الاقتصادية الملحوظة من خلال استراتيجية تدريب متطورة ومتعددة الأوجه تركز على تعظيم مهارات الاستدلال دون إنفاق حسابي مفرط.
التقنيات الأساسية التي تدعم هذا التخصص الفعال شملت:
- الضبط الدقيق تحت الإشراف (SFT): تضمنت هذه المرحلة التأسيسية تدريب النموذج الأساسي على مجموعة بيانات عالية الجودة ومنسقة من أزواج المشكلات والحلول المصممة خصيصًا للاستدلال الرياضي المتقدم. من خلال SFT، تعلم النموذج محاكاة مسارات حل المشكلات الصحيحة والاستنتاج المنطقي.
- التعلم المنهجي التكراري (Iterative Curriculum Learning): بدلاً من تعريض النموذج للنطاق الكامل لصعوبة المشكلات دفعة واحدة، تقدم هذه الاستراتيجية التحديات بطريقة متدرجة. يبدأ النموذج بمسائل رياضية أبسط وينتقل تدريجيًا إلى مسائل أكثر تعقيدًا، مثل تلك الموجودة في AIME و HMMT. هذا النهج المنظم يسهل تعلمًا أكثر استقرارًا وفعالية، مما يسمح للنموذج ببناء أساس قوي قبل معالجة المهام شديدة الصعوبة. كانت هذه التقنية أساسية لتطوير نموذج سابق رئيسي،
Fathom-R1-14B-V0.6. - دمج النماذج (Model Merging): نموذج Fathom-R1-14B النهائي هو دمج لنموذجين سابقين تم ضبطهما بدقة:
Fathom-R1-14B-V0.6(الذي خضع لـ Iterative Curriculum SFT) وFathom-R1-14B-V0.4(الذي ركز على SFT مع "Shortest-Chains"، مما يرجح أنه يركز على الإيجاز في الحلول). بدمج النماذج التي تم تدريبها بتركيزات مختلفة قليلاً، يرث النموذج الناتج مجموعة أوسع من نقاط القوة.
كان الهدف الشامل لعملية التدريب الدقيقة هذه هو غرس "استدلال رياضي موجز ودقيق في نفس الوقت".
استكشفت Fractal AI Research أيضًا مسار تدريب بديل مع نسخة تسمى Fathom-R1-14B-RS. تضمنت هذه النسخة التعلم المعزز (RL)، باستخدام خوارزمية يشار إليها باسم GRPO (Generalized Reward Pushing Optimization)، جنبًا إلى جنب مع SFT. بينما حقق هذا النهج أداءً عاليًا مماثلًا، كانت تكلفة ما بعد التدريب أعلى قليلاً، حيث بلغت 967 دولارًا أمريكيًا. يؤكد تطوير كلا الإصدارين على الالتزام باستكشاف منهجيات متنوعة لتحقيق أداء استدلال مثالي بكفاءة. كجزء من التزامهم بالشفافية، قامت Fractal AI Research بنشر وصفات التدريب ومجموعات البيانات كمصادر مفتوحة.
معايير الأداء: قياس تميز الاستدلال
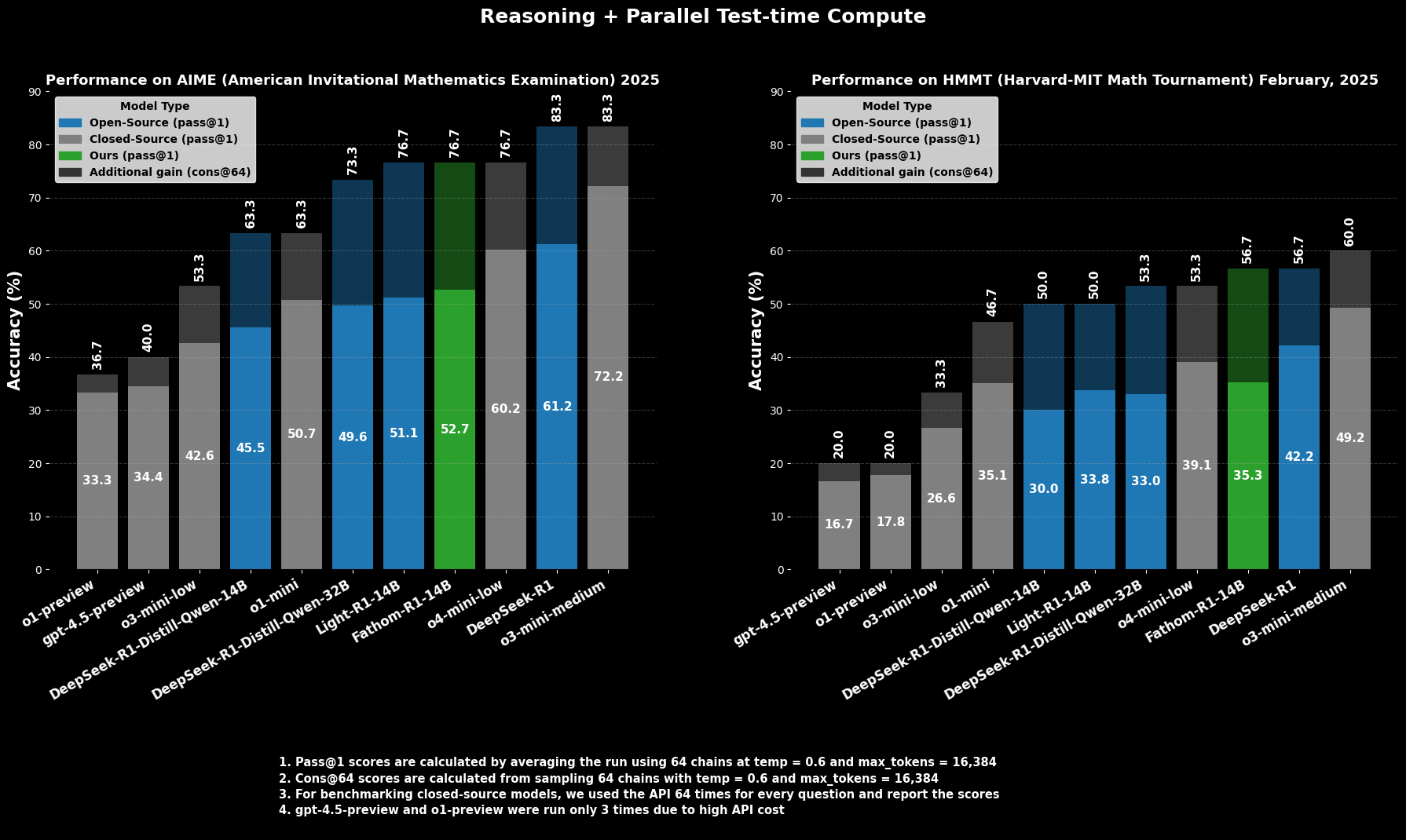
كفاءة Fathom-R1-14B ليست نظرية بحتة؛ بل هي مدعومة بأداء مبهر على معايير الاستدلال الرياضي الصارمة والمعترف بها دوليًا.
النجاح في AIME و HMMT
في AIME2025 (الامتحان الأمريكي الرياضي الدعوي)، وهي مسابقة رياضيات صعبة للمرحلة ما قبل الجامعية، يحقق Fathom-R1-14B دقة Pass@1 تبلغ 52.71%. يشير مقياس `Pass@1` إلى النسبة المئوية للمسائل التي يولد النموذج لها حلاً صحيحًا في محاولة واحدة. عند السماح بميزانية حسابية أكبر وقت الاختبار، والتي يتم تقييمها باستخدام cons@64 (التناسق بين 64 حلاً تم أخذ عينات منها)، ترتفع دقته في AIME2025 إلى نسبة مبهرة تبلغ 76.7%.
وبالمثل، في HMMT25 (بطولة الرياضيات بجامعتي هارفارد ومعهد ماساتشوستس للتكنولوجيا)، وهي مسابقة أخرى رفيعة المستوى، يحقق النموذج 35.26% Pass@1، والتي تزيد إلى 56.7% cons@64. هذه النتائج جديرة بالملاحظة بشكل خاص لأنها تحققت ضمن ميزانية مخرجات النموذج البالغة 16 ألف رمز، مما يعكس اعتبارات النشر العملي.
الأداء المقارن
في التقييمات المقارنة، يتفوق Fathom-R1-14B بشكل كبير على النماذج مفتوحة المصدر الأخرى ذات الأحجام المماثلة أو حتى الأكبر على هذه المعايير الرياضية المحددة عند `Pass@1`. الأكثر إثارة للإعجاب، أن أداءه، خاصة عند النظر في مقياس `cons@64`، يضعه في منافسة مع بعض النماذج المغلقة المصدر القادرة، والتي يُفترض غالبًا أنها تتمتع بوصول إلى موارد أكبر بكثير. هذا يسلط الضوء على كفاءة Fathom-R1-14B في ترجمة معلماته وتدريبه إلى استدلال عالي الدقة.
دعنا نحاول تشغيل Fathom-R1-14B
https://nodeshift.com/blog/how-to-install-fathom-r1-14b-the-most-efficient-sota-math-reasoning-llm
يقدم هذا القسم دليلًا مركزًا حول تشغيل Fathom-R1-14B باستخدام مكتبة transformers من Hugging Face ضمن بيئة Python. هذا النهج مناسب تمامًا للمستخدمين الذين لديهم إمكانية الوصول إلى أجهزة GPU قوية، سواء محليًا أو من خلال مزودي الخدمات السحابية. تتبع الخطوات الموضحة هنا عن كثب الممارسات المعمول بها لنشر مثل هذه النماذج.
تهيئة البيئة
يعد إعداد بيئة Python مناسبة أمرًا بالغ الأهمية. توضح الخطوات التالية إعدادًا شائعًا باستخدام Conda على نظام يعتمد على Linux (أو Windows Subsystem for Linux):
الوصول إلى جهازك: إذا كنت تستخدم جهاز GPU سحابيًا عن بُعد، فاتصل به عبر SSH.Bash
# Example: ssh your_user@your_gpu_instance_ip -p YOUR_PORT -i /path/to/your/ssh_key
التحقق من التعرف على وحدة معالجة الرسومات (GPU): تأكد من أن النظام يتعرف على وحدة معالجة الرسومات NVIDIA وأن برامج التشغيل مثبتة بشكل صحيح.Bash
nvidia-smi
إنشاء وتنشيط بيئة Conda: من الممارسات الجيدة عزل تبعيات المشروع.Bash
conda create -n fathom python=3.11 -y
conda activate fathom
تثبيت المكتبات الضرورية: قم بتثبيت PyTorch (المتوافق مع إصدار CUDA الخاص بك)، و transformers من Hugging Face، و accelerate (لتحميل النموذج وتوزيعه بكفاءة)، و notebook (لـ Jupyter)، و ipywidgets (لتفاعلية دفتر الملاحظات).Bash
# Ensure you install a PyTorch version compatible with your GPU's CUDA toolkit
# Example for CUDA 11.8:
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Or for CUDA 12.1:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
conda install -c conda-forge --override-channels notebook -y
pip install ipywidgets transformers accelerate
الاستدلال المستند إلى Python في دفتر ملاحظات Jupyter
مع تجهيز البيئة، يمكنك استخدام دفتر ملاحظات Jupyter لتحميل Fathom-R1-14B والتفاعل معه.
بدء خادم دفتر ملاحظات Jupyter: إذا كنت على خادم بعيد، فابدأ تشغيل Jupyter Notebook للسماح بالوصول عن بُعد وحدد منفذًا.Bash
jupyter notebook --no-browser --port=8888 --allow-root
إذا كنت تقوم بالتشغيل عن بُعد، فمن المحتمل أن تحتاج إلى إعداد إعادة توجيه منفذ SSH من جهازك المحلي للوصول إلى واجهة Jupyter:Bash
# Example: ssh -N -L localhost:8889:localhost:8888 your_user@your_gpu_instance_ip
ثم، افتح `http://localhost:8889` (أو المنفذ المحلي الذي اخترته) في متصفح الويب الخاص بك.
كود Python للتفاعل مع النموذج: أنشئ دفتر ملاحظات Jupyter جديدًا واستخدم كود Python التالي:Python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Define the model ID from Hugging Face
model_id = "FractalAIResearch/Fathom-R1-14B"
print(f"Loading tokenizer for {model_id}...")
tokenizer = AutoTokenizer.from_pretrained(model_id)
print(f"Loading model {model_id} (this may take a while)...")
# Load the model with bfloat16 precision for efficiency and device_map for auto distribution
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # Use bfloat16 if your GPU supports it
device_map="auto", # Automatically distributes model layers across available hardware
trust_remote_code=True # Some models may require this
)
print("Model and tokenizer loaded successfully.")
# Define a sample mathematical prompt
prompt = """Question: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. In June, she sold 4 more clips than in May. How many clips did Natalia sell altogether in April, May, and June? Provide a step-by-step solution.
Solution:"""
print(f"\nPrompt:\n{prompt}")
# Tokenize the input prompt
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Ensure inputs are on the model's device
print("\nGenerating solution...")
# Generate the output from the model
# Adjust generation parameters as needed for different types of problems
outputs = model.generate(
**inputs,
max_new_tokens=768, # Maximum number of new tokens to generate for the solution
num_return_sequences=1, # Number of independent sequences to generate
temperature=0.1, # Lower temperature for more deterministic, factual outputs
top_p=0.7, # Use nucleus sampling with top_p
do_sample=True # Enable sampling for temperature and top_p to have an effect
)
# Decode the generated tokens into a string
solution_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\nGenerated Solution:\n")
print(solution_text)
الخلاصة: تأثير Fathom-R1-14B على الذكاء الاصطناعي المتاح
يمثل FractalAIResearch/Fathom-R1-14B عرضًا مقنعًا للبراعة التقنية في ساحة الذكاء الاصطناعي المعاصرة. تصميمه المحدد، الذي يتميز بحوالي 14.8 مليار معلمة، وهندسة Qwen2 المعمارية، ونافذة سياق 16 ألف رمز، عندما يُدمج مع تدريب رائد وفعال من حيث التكلفة (حوالي 499 دولارًا للإصدار الأساسي)، قد أدى إلى نموذج لغة كبير (LLM) يقدم أداءً متقدمًا. يتجلى ذلك في نتائجه على معايير الاستدلال الرياضي الشاقة مثل AIME و HMMT.
يوضح Fathom-R1-14B بشكل مقنع أنه يمكن تطوير حدود الاستدلال في الذكاء الاصطناعي من خلال التصميم الذكي والمنهجيات الفعالة، مما يعزز مستقبلًا يكون فيه الذكاء الاصطناعي عالي الأداء أكثر ديمقراطية وأوسع فائدة.
هل تريد منصة متكاملة وشاملة (All-in-One) لفريق المطورين لديك للعمل معًا بأقصى قدر من الإنتاجية؟
Apidog يلبي جميع متطلباتك، ويحل محل Postman بسعر معقول جدًا!